
본격 페이지랭크 알고리즘 파헤치기
[꼭꼬의 매드매스 031] 네트워크분석④ 페이지랭크 알고리즘


오늘 매드매스에 다룰 주제는 네트워크 특집 마지막이라네. 원래 저번 주 특집을 끝으로 마무리하려고 하였으나 어떤 벗이 이런 피드백을 남겨주셨더구만.
"구글 뉴스 내용이 흥미로웠어요. 다만 페이지랭크가 무엇인지 더 자세히 다뤄주시면 좋을 것 같아요!"
피드백 장인 꼭꼬가 이 의견을 그냥 넘길 수 없지.🤓 그래서 오늘은 본격 피드백 반영 특집 네트워크 4탄이라네. 페이지랭크 알고리즘이 어떤 알고리즘인지 최대한 친절하게 설명을 하도록 하겠네. 벗들은 마음의 준비만 단단히 하면 된다네. 확률과 행렬에 대한 간단한 이해가 있는 벗이라면 더 머리에 쏙쏙 박힐 걸세👀
1. 인접행렬 만들기
기본적인 원칙은 고유벡터 중심성 지표와 같네. 지난 매드매스에서 이야기한 것 처럼 고유벡터 중심성 지표의 핵심은 “핵심 노드와 연결된 노드가 중요하다”가 핵심일세. 이것을 기억해 두고 예시 네트워크를 보면서 차근차근 다가가 보겠네.

위의 그래프에 나타난 것 처럼 A부터 E까지 총 5개의 페이지가 있다고 해보겠네. 그리고 그 페이지에는 서로의 링크가 심어져 있지. 그 링크는 화살표로 표현해봤네. 가령 A 페이지는 B와 C 페이지로 갈 수 있는 링크가 심어져 있는 것이고, E 페이지에는 D로 갈 수 있는 링크가 있는 것이지. 이걸 조금 더 보기 편하게 정리를 해보면 A → {B, C} / B → {C, E} / C → {A, E} / D → {A, B, C} / E → {D} 로 표현할 수 있겠구만. 수학적으로 표현하면 아래와 같은 행렬로 정리할 수 있겠군.

두려워말게나! 차근차근 이해하다 보면 어렵지 않을 걸세. 위 행렬의 열이 각 페이지에 있는 링크를 표시한 거라네(행렬의 가로줄은 행, 세로줄은 열이라네). 첫 번째 열을 보게나. A에서 출발해서 B, C로 갈 수 있으니 B와 C 행에 1이 표시되어있지? 동일한 논리로 모든 열을 채우면 위와 같은 행렬이 만들어질 걸세. 그리고 우리는 이 행렬을 인접행렬(Adjacency matrix)이라고 하겠네.
2. 확률행렬 구하기
다음 해야 할 일은 이 인접행렬을 바탕으로 확률행렬을 만들어주어야 한다는 것이네. 확률행렬은 말 그대로 각 페이지로 갈 확률을 보여주는 행렬이라네. 확률이라는 단어에 겁먹을 필요 없네. 아주 단순한 구조이니 걱정하지 말게나.
자 일단, A 페이지에서 갈 수 있는 선택지는 어디인지 생각해보게나. 우리가 인접행렬로 표시한 열에서 1로 적어둔 B와 C 두 곳뿐일 거네. 즉 A 페이지에 들어가면 B와 C 두 개의 페이지 중 한 곳을 가야 하니 각각의 페이지는 1/2의 확률을 가질 걸세. 다른 페이지에도 동일한 논리로 확률을 작성할 수 있겠지? D 페이지는 A, B, C 총 3개의 선택지가 있으니 각각의 페이지를 선택할 확률은 1/3이겠구만. 정리하면 아래와 같은 확률행렬을 만들 수 있을 거라네.

확률행렬을 구했다면 다 온 것이라네. 이 행렬에 처음에 각 페이지를 선택할 확률을 곱한다면 최종적으로 각 사이트에 방문할 확률을 구할 수 있게 되는 것이지. 아래 식을 참고하게나! 하지만 이동이 딱 한 번 이뤄질 보장은 없고 페이지 안에서 계속 링크를 타고, 타고 이동할 수 있으니 곱셈을 한 번만 하면 안 될 걸세.

한 번만 곱하면 1번 이동했을 때 각 페이지를 방문할 확률이 나오고, 이 결과값에 또 확률행렬을 곱하면 2번 이동했을 때의 페이지 방문 확률이 나오는 것이지. 그런데 신기한 것이 이 곱셈을 계속해서 반복하면 어느 순간부터는 확률이 변하지 않고 고정값으로 나온다는 사실이라네! 그리고 이 값을 바로 각 사이트의 PageRank라고 명명한 것이지.
3. 페이지랭크 구하기
다 왔네. 이제 각 사이트에 처음으로 방문할 확률에 숫자를 넣어보고 실제 페이지랭크 값을 구해보겠네. A부터 E까지 각각의 사이트에 방문할 확률이 동일하게 1/5이라고 하고 계산을 진행해 보겠네. 우리가 구한 확률행렬을 이용해 수식을 써보면 이렇게 될 걸세.
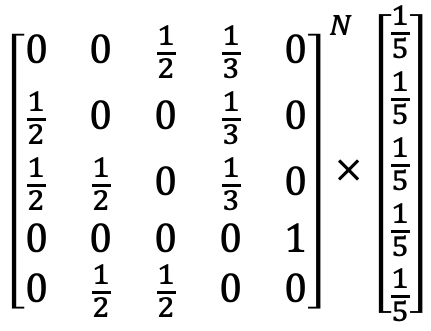
그리고 확률행렬과 곱해보면 아래와 같은 수치가 나온다네. 여러 번 방문할 때마다(즉, 여러 번 곱해질 때마다) 확률이 요동치지만 5회만 넘어가도 수치가 잠잠해지고 10회 이상이 되면 고정된 수치로 수렴하는 걸 확인할 수 있네. A 페이지의 확률은 0.19, B 페이지는 0.16, C 페이지는 0.24, D와 E는 0.20으로 나왔네. 이 수치가 바로 각 페이지의 페이지랭크가 되는 것이지.
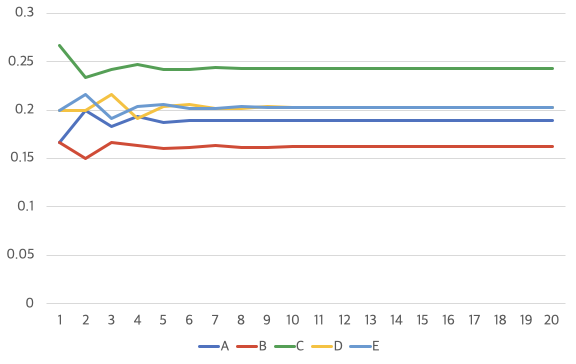
신기한 것은 처음에 사이트에 방문할 확률이 달라지더라도 페이지랭크 값은 동일하게 나온다는 것이네. 이번에는 각 페이지마다 확률을 다르게 설정해보겠네. 1/2, 1/3, 1/4, 1/5, 1/6을 넣어서 계산을 해보면, 결과는? 이전보다는 초반 확률이 훨씬 더 요동치지만 10회를 넘어가자 이전과 같은 동일한 값이 나오고 있구만!

4. 마무으리
이것이 바로 구글 검색 알고리즘인 페이지랭크라네. 물론 실제 논문에는 이보다 조금 더 복잡한 요소들이 포함되어 있네. 소개한 확률행렬을 바로 사용하는 게 아니라 감쇄 상수를 추가하기도 하지. 참고로 감쇄 상수(damping factor)는 논문 표현을 빌리자면 “웹서핑을 하는 사람이 그 페이지에 만족하지 않고 다른 페이지 링크를 클릭할 확률“을 적용한 수치일세.
일부 언론학자들은 이 감쇄 상수에 구글의 통제 전략이 담겨있을 수 있다고 비판하기도 한다네. 페이지랭크 알고리즘으로 나온 수치가 아니다 싶으면 감쇄 상수 값을 수정하면서 보정한다는 것이지. 구글이 생각하는 좋은 결과가 나오도록 조정을 할 테니 자연스럽게 구글의 편집권이 반영될 것이고. 여튼 오늘 매드매스는 조금 분량이 길어졌구만. 다음에도 벗들이 피드백 보내주면 바로바로 반영을 할 터이니 언제든 의견 보내주시게. 그럼 다음 시간까지 안뇽~!