
성중립 언어
마부뉴스 CHART & DATA & SOURCE


마부뉴스에서 사용된 데이터와 원 출처를 확인할 수 있는 공간입니다. Graph Details에서는 레터에서 간단하게 소개된 그래프를 조금 더 자세하게 설명해드립니다. Data에서는 레터에서 활용한 다양한 데이터 소스들을 확인할 수 있습니다. 직접 데이터를 가지고 분석에 활용해보세요. Article에는 마부뉴스가 레터를 쓰면서 참고한 기사 목록을 담아두었습니다. 궁금한 부분이 있다면 댓글을 남겨주세요!
Graphic Details
Gender stereotypes are reflected in the distributional structure of 25 languages

성차별적 언어가 실제 성차별적 인식에 미치는 영향을 파악한 논문 자료입니다.
39개국의 657,335명, 25개 언어 데이터에서 성별 연관성을 조사하고 성 고정관념이 강한 언어(경력과 성별 연관성이 더 강한 언어)가 해당 언어 화자에서 더 강력한 성 고정관념(성별 연관성)을 예측하는지 확인했습니다.
전세계의 언어 중 25개 언어를 대상으로 연구를 진행했는데, 젠더 연관성이 강한 언어(남녀 구분이 강한 언어)를 사용하는 사람들은 젠더 고정관념이 더 강한 경향이 있는 것으로 나타났습니다.
개인 수준에서 문화적 고정관념을 정량화하는 데 널리 사용되는 방법인 내재적 연관 검사(IAT) 데이터와 성 고정관념(남성과 직업을 연관시키는 경향, 여성을 가족과 연관시키는 경향)을 측정한 데이터를 활용한 자료입니다.
활용한 데이터와 분석 방법 등 좀 더 자세한 자료는 저자 Github에서 더 확인할 수 있습니다.
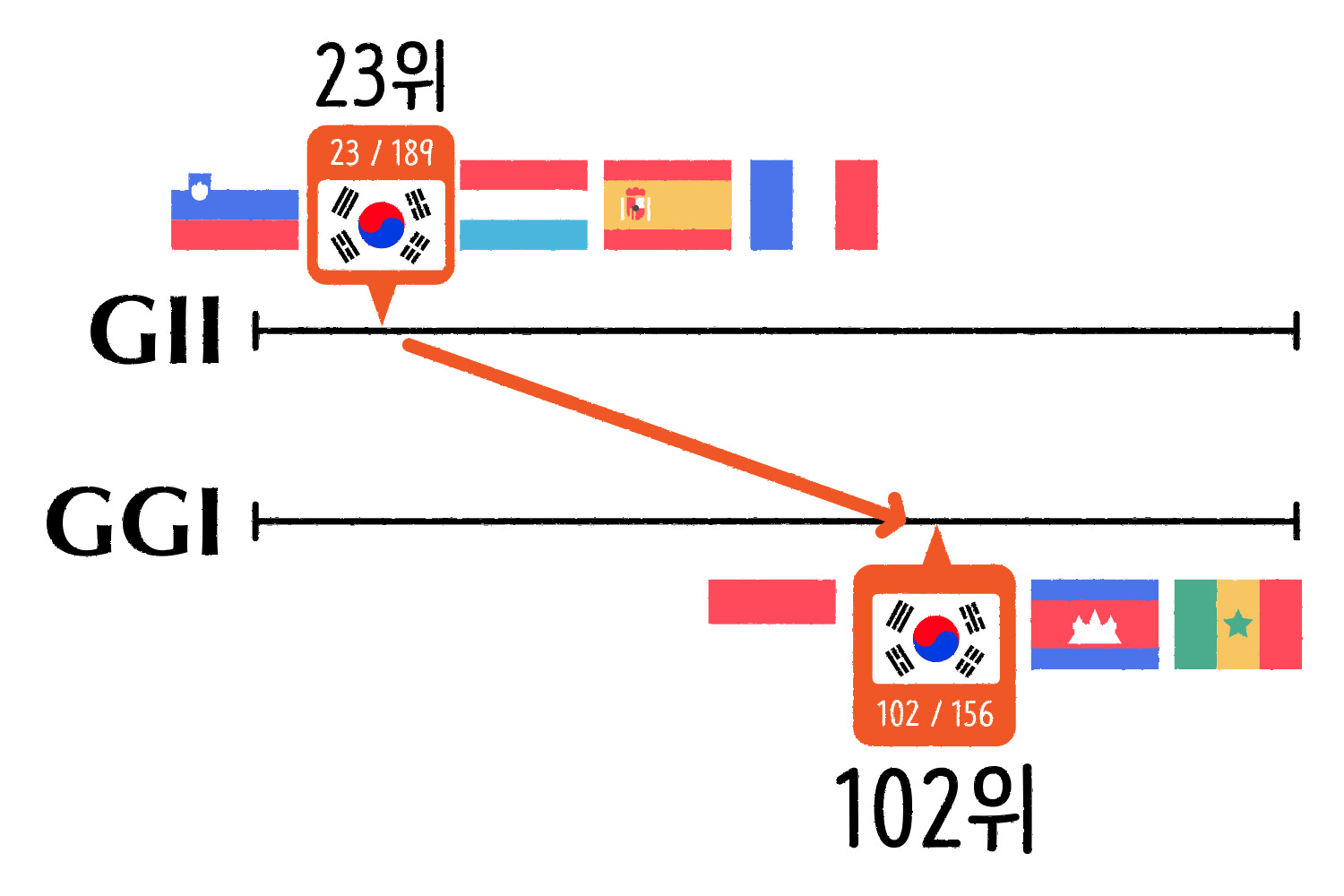
대한민국의 성평등 지수

UN의 산하기관인 유엔개발계획(UNDP)에서 제공하고 있는 성불평등 지수 GII(Gender Inequality Index)와 세계경제포럼(WEF)에서 발표하고 있는 성격차 지수 GGI(Gender Gap Index)를 활용했습니다.
2020년 기준으로 우리나라의 GII 순위는 전 세계 189개국 중 23위입니다.
GGI는 2021년 기준으로 156개국 중 102위로 하위권입니다. GII와 동일한 시점으로 비교해보면 2020년엔 153개국 중 108위로 더 순위가 낮습니다.

GGI와 GII에서 활용하는 지표들을 정리한 자료입니다.
출처 : https://www.nocutnews.co.kr/news/5041598


Data
Article
Can Gender-Fair Language Reduce Gender Stereotyping and Discrimination?
Gender stereotypes are reflected in the distributional structure of 25 languages
Language influences mass opinion toward gender and LGBT equality